-
 @ThothChildren
@ThothChildren
- 2018.7.15
- PV 367
SAGAN
ー 概要 ー
SAGAN(Self Attention Generative Adversarial Network)はACGANやSNGANでも扱う画像生成タスクにおいてSelf Attention機構を導入することで高精度な画像生成を実現したネットワーク.




この章を学ぶ前に必要な知識
条件
- クラスラベルを入力
- SelfAttentionと通常入力の値の比率を決めるγを決めておく
効果
- クラスを指定してもらい128x128の高解像度な画像を生成
ポイント
- SelfAttention機構をGeneratorとDiscriminatorに導入して精度向上
- Spectrum NormalizationをGeneratorとDiscriminatorに導入して学習安定
- Discriminatorの学習率よりGeneratorの学習率を小さくするTTURを採用
解 説
SAGAN(Self Attention Generative Adversarial Network)はACGANやSNGANで扱うようなImageNetを用いた画像生成タスクにおいて、Self Attention機構を導入することで高精度な画像生成を実現したネットワーク.
改善に至った工夫
・Self Attention機構をGenerator及びDiscriminatorに加える
・Spectral NormalizationをGenerator及びDiscriminatorに加える
・Discriminatorの学習率よりGeneratorの学習率が小さくなるようにする(TTUR)
などが挙げられる | 外部リンク SAGANの論文 |
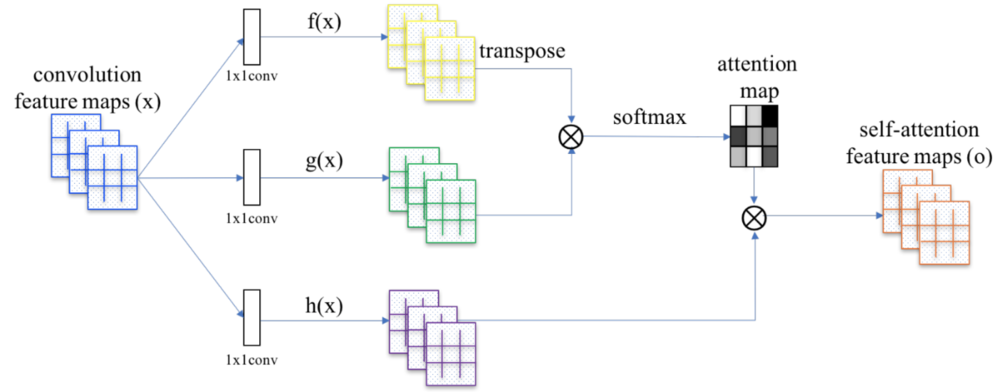 | Self Attention機構の説明.(論文より引用)
f(x)とg(x)の積をとることで、全画素同士で類似しているものを算出している.softmaxによって正規化.
類似している箇所に対してスケールさせるh(x)を掛け合わせself-attention feature mapを算出している. |
f(x)とg(x)に関して少しだけ詳しくどのような計算が行われいるかと説明しているのが以下の図.
\(f(x),g(x)\)は\(f(x)=W_f x\), \(g(x)=W_g x\) の式で表され、\(x\)を入力に線形変換を行っているのみ.
これらの線形変換の係数\(W_f,W_g\)(\(W_h\)も)が学習するパラメータとなる.
これらから全画素同士の類似度を計算したのちにsoftmaxで各画素ごとに要素が足して1になるように変換.
その出力と\(h(x)\)を掛け合わせて\(o\)を出力する | f(x)とg(x)の計算について |
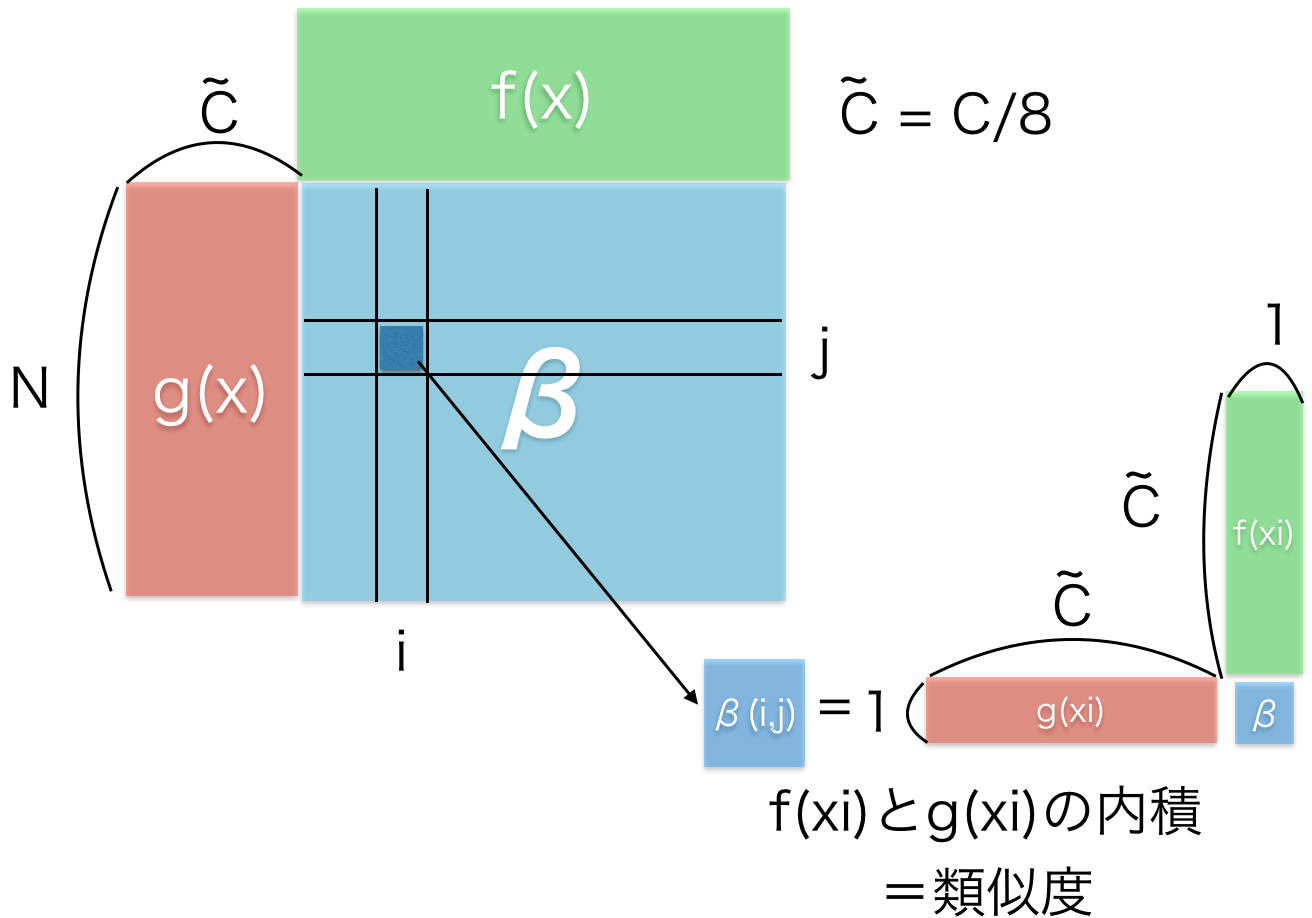 | f(x)とg(x)の積は、全画素同士の類似度を各求めている.
(https://urusulambda.wordpress.com/ より引用) |
肝心なSelf Attention機構のネットワークへの導入の方法は単純に入力\(x\)とあらかじめ決めておくパラメータ\(\gamma \)を使って
$$y = \gamma o +x$$
で表される.すなわち以下のような図になる. | Self Attention機構のネットワークへの導入 |
 | SelfAttention機構のネットワークへの入れ方
(https://urusulambda.wordpress.com/ より引用.)
|
 | 左の各点をサンプルしたときにそれぞれの画素から計算されたAttention Map.
色やテクスチャが似ているところが白く強調される.
上の段の人形であれば、目の画素のサンプルは他の目の領域と強く反応している.
このようにSelf Attention機構を利用することでConvolution層とPooling層の組み合わせでは得られなかったような画像全体の大域的な情報を利用することが可能になる. |
| 実際にSAGANによって生成された128x128の画像. |
この章を学んで新たに学べる
Comments