-
 @ThothChildren
@ThothChildren
- 2018.9.16
- PV 234
SegNet
ー 概要 ー
SegNetはFCNより解像度よくSemanticSegmentationを行うことができるネットワーク.UnPooling層をDecoderに用いることでより細かい領域分割ができることを可能にした.またUnpoolingを用いて省メモリになったことも特徴.



この章を学ぶ前に必要な知識
条件
- 任意のサイズの画像が入力
効果
- 各画素ごとにクラス分類を行う(Semantic Segmentation)
- FCNより解像度が高く、省メモリ高速となっている
ポイント
- DecoderにおいてUnpooling層を用いたことが特徴.
解 説
元の論文へのリンクを貼っておきます. | 外部リンク 元論文 |
SegNetはFCNより解像度よくSemanticSegmentationを行うことができるネットワーク.
基本的な構造はEncoder-Decoderモデルと似通ってはいますが、
UnPooling層をDecoderに用いることでより細かい領域分割ができることを可能にしています.
またUnpoolingを用いて省メモリになったことも特徴です. | SegNetとは |
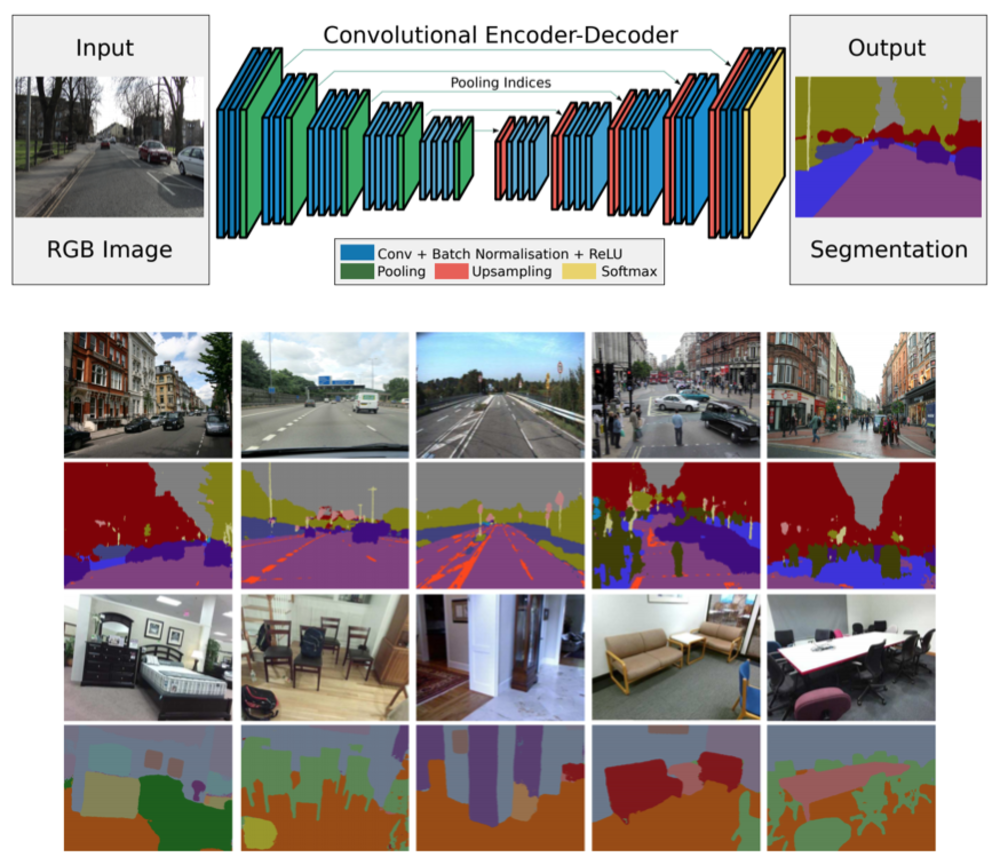
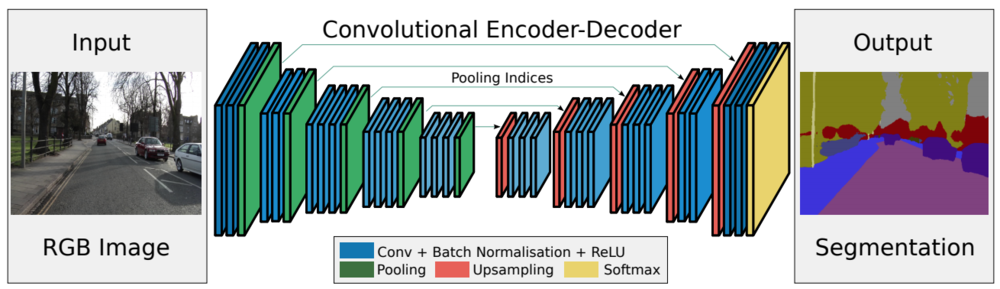 | SegNetのネットワーク構造.
図の左側をEncoder、
図の右側をDecoderと呼びます.
各層が描かれていますが、赤色のUpsampling層が今回特徴となっており、省メモリ化や高解像度化に寄与しています.
(図は論文より引用) |
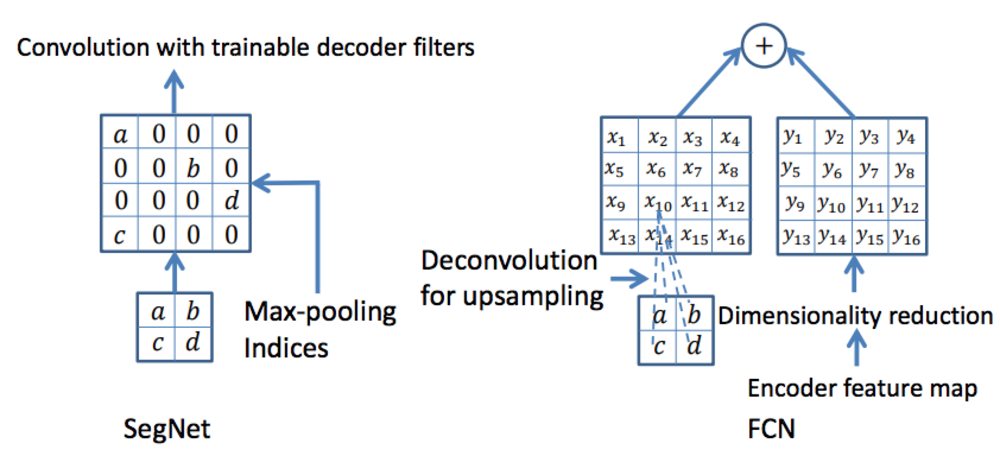 | 論文にて説明されているDecoderにおけるSegNetとDCNの違い.
SegNetにおけるUpsamplingでは、Encoderの時にMaxPoolingを取った画素を覚えておき、Decoderのタイミングで同じ位置の画素に入力を戻します. |
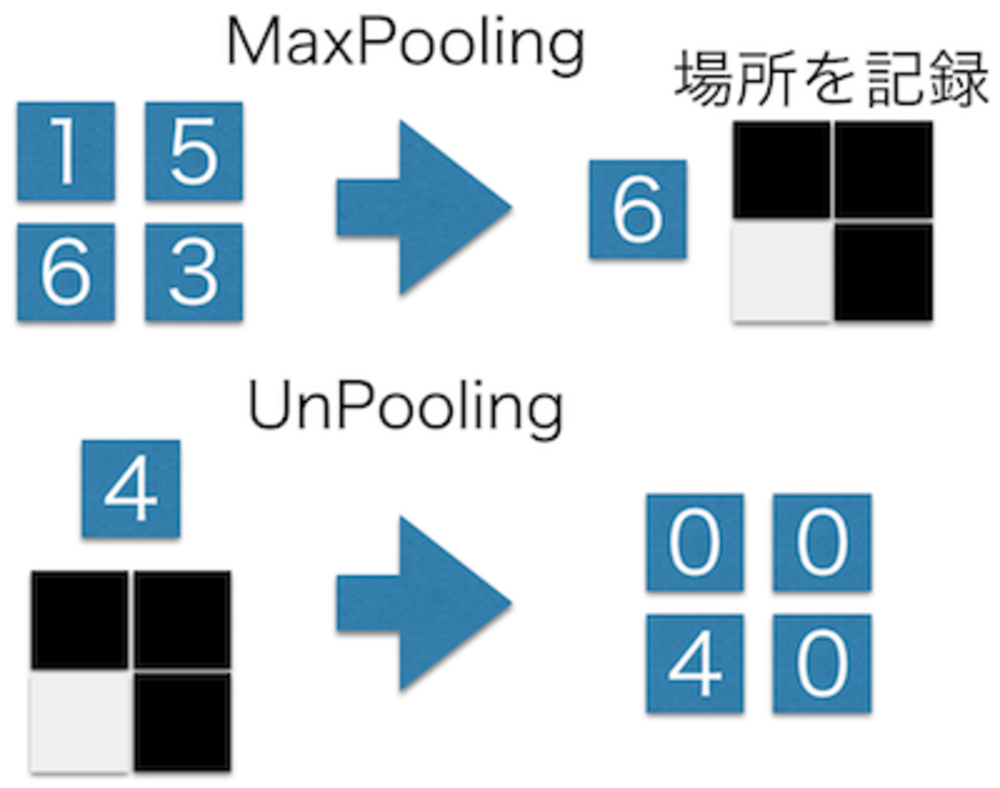
UnPooling層は、EncoderでMaxPoolingで採用した画素を記録しておき、Decoder時にその情報を元に入力を戻していく層.
より正確な位置に値をフィードバックさせていくことができ、より精度のよい領域分割が可能になります.
値が採用されていない画素は0埋めされますが、上記の画像のようにUnpooling層のあとには、パラメータを持ち学習可能なConvolution層が何層か続くため、次のUnpoolingまでには画素に0はなくなっていきます. | UnPooling層 |
この章を学んで新たに学べる
Comments