-
 @ThothChildren
@ThothChildren
- 2018.12.8
- PV 1311
Attention機構
ー 概要 ー
Attention機構(注意機構)とは、主に機械翻訳や画像処理等を目的としたEncoder-Decoderモデルに導入される要素ごとの関係性、注意箇所を学習する機構.機械翻訳において翻訳対象の単語間の関係性や全体のコンテキストを考慮させるために考案されたものだが、画像処理などにおいても応用されている.



この章を学ぶ前に必要な知識
条件
- RNNやLSTMでエンコーダデコーダモデルになっているネットワークなど
ポイント
- 単語の関係性を学習させて機械翻訳の性能を向上させた
- Decoderの注目ユニットの隠れ層を推定するときにEncoderから算出されるコンテキストを考慮
- 機械翻訳だけでなく、画像処理にも応用される例が多い
- 注目機構にも学習するパラメータを持つ
解 説
Attention機構(注意機構)とは、主に機械翻訳や画像処理等を目的としたEncoder-Decoderモデルに導入される要素ごとの関係性、注意箇所を学習する機構.
機械翻訳において翻訳対象の単語間の関係性や全体のコンテキストを考慮させるために考案されたものだが、画像処理などにおいても応用されている. | Attention機構とは |
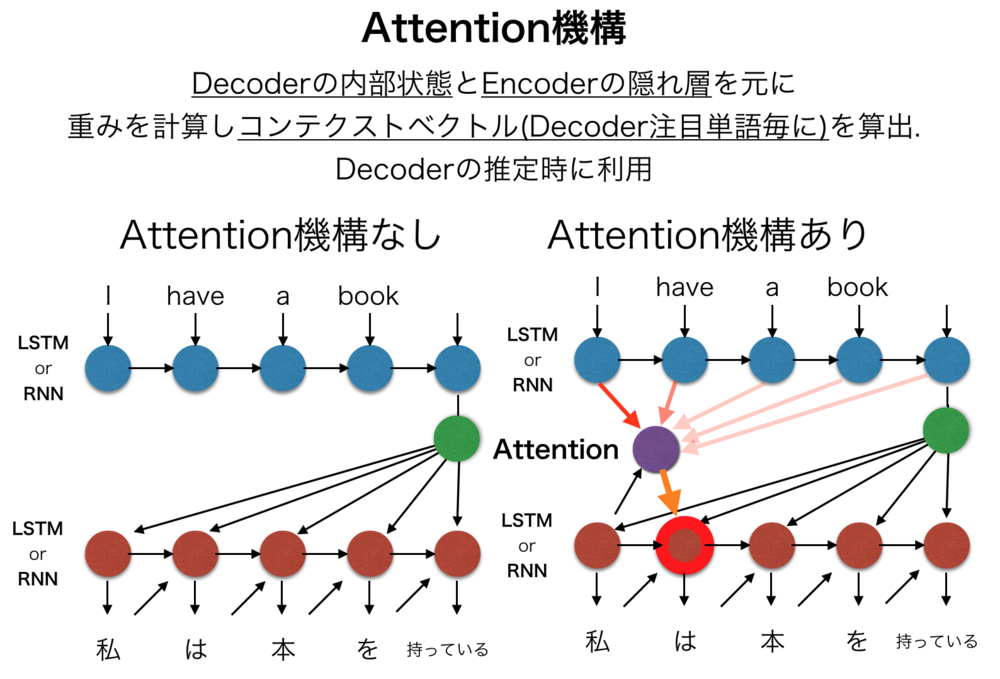
Attention機構を導入する前の機械翻訳においては、
Encoder(入力文字列を符号化するエンコーダ部分)とDecoder(符号化された入力を復号化し別言語にするデコーダ部分)のみで構成されていた.
EncoderやDecoderには、それぞれRNN, LSTMなどの時系列データ用のNNが組まれていたが、それらの間の受け渡しは単一の固定長の隠れ層(Hidden Layer)のみによって渡されることが多かった.Decoderでは、渡されたHidden Layerのベクトルと一つ前の翻訳単語ベクトルから今回の単語を推定していた.
Attention機構では、新たに「"Decoderにて翻訳しようとしているi番目のtargetの単語翻訳時の内部状態"と"Encoderでの各単語の隠れ層"を使って計算されるコンテキストベクトル」をDecoderの推定時に使用している.
そのため、Attention機構を含むモデルでは、
i番目の単語を出力するときに、入力として
・一つ前の翻訳単語結果
・Decoderの内部状態
・Attentionより算出されたコンテキストベクトル
を与えられ、それを元にi番目の単語推定を行う. | Attention機構の仕組み |
Attention機構の処理の詳細についてまとめます.
Decoderの\(t\)番目の出力を推定するものとします.
入力
・今から出力するDecoderの内部状態 : \(hd_t\)
・一つ前に出力したDecoderの内部状態 : \(hd_{t-1}\)
・一つ前にDecoderが出力した結果 : \(s_{t-1}\)
・Encoderの各ユニットが持つ隠れ層: \(he_i\)
・Attention機構で算出されたコンテキストベクトル : \(c_{t}\)
attention機構では\(t\)番目の単語を推定しようとするたびにコンテキストベクトル\(c_{t}\)を計算します.
Encoderの隠れ層とDecoderの内部状態から重み計算
コンテキストベクトル\(c_t\)は最終的にEncoderの全隠れ層ベクトル\(h\)の重み付け和で計算されます.
そのためにまず重みの計算を行う必要があります.
重み付けを行うにあたり何らかの\(Score\)関数(様々です)を用意して、各隠れ層\(he_i\)とDecoder内部状態\(hd_{t-1}\)とでどれほど関係あるかを数値化して重み係数を求めます.
$$\alpha_i = \frac{exp(score(he_i, hd_{t-1})}{\sum_{j=0} exp(score(he_j, hd_{t-1}))}$$
\(\alpha_i\)はi番目のencoder隠れ層ベクトル\(he_i\)に対する重みです.
重みからコンテキストベクトルを算出
上記の重みを元にコンテクストベクトル\(c_t\)を求めます.
$$c_t = \sum_i \alpha_i \cdot he_i $$
上記のコンテクストベクトルは重要な\(he_i\)を参考に次のDecoderの内部状態を推定する材料の一つになります.
次の内部ベクトル状態の推定
最後に今まで求めたベクトルを用いて\(t\)番目の単語推定のためのDecoder内部状態\(hd_t\)を求めます.
この求め方も様々です.
$$hd_t = f(c_t, hd_{t-1}, s_{t-1})$$ | Attention機構の詳細 |
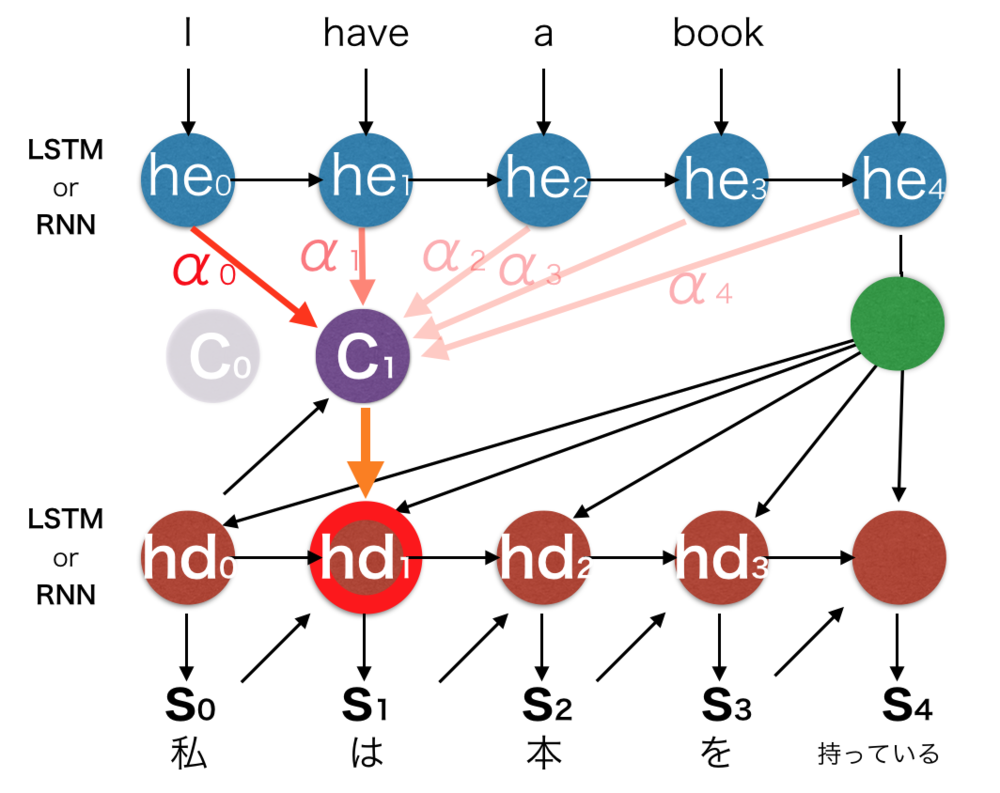 | 上記解説の概念図.
全ての対応する変数を記入した. |
多くの場合、Attention機構は重み算出のためのスコアリング時や内部変数の推定時に重み付けのパラメータを持つ.
学習時にそれらは学習されて重みづけの特徴を獲得する. | Attention機構補足 |
この章を学んで新たに学べる
Comments