





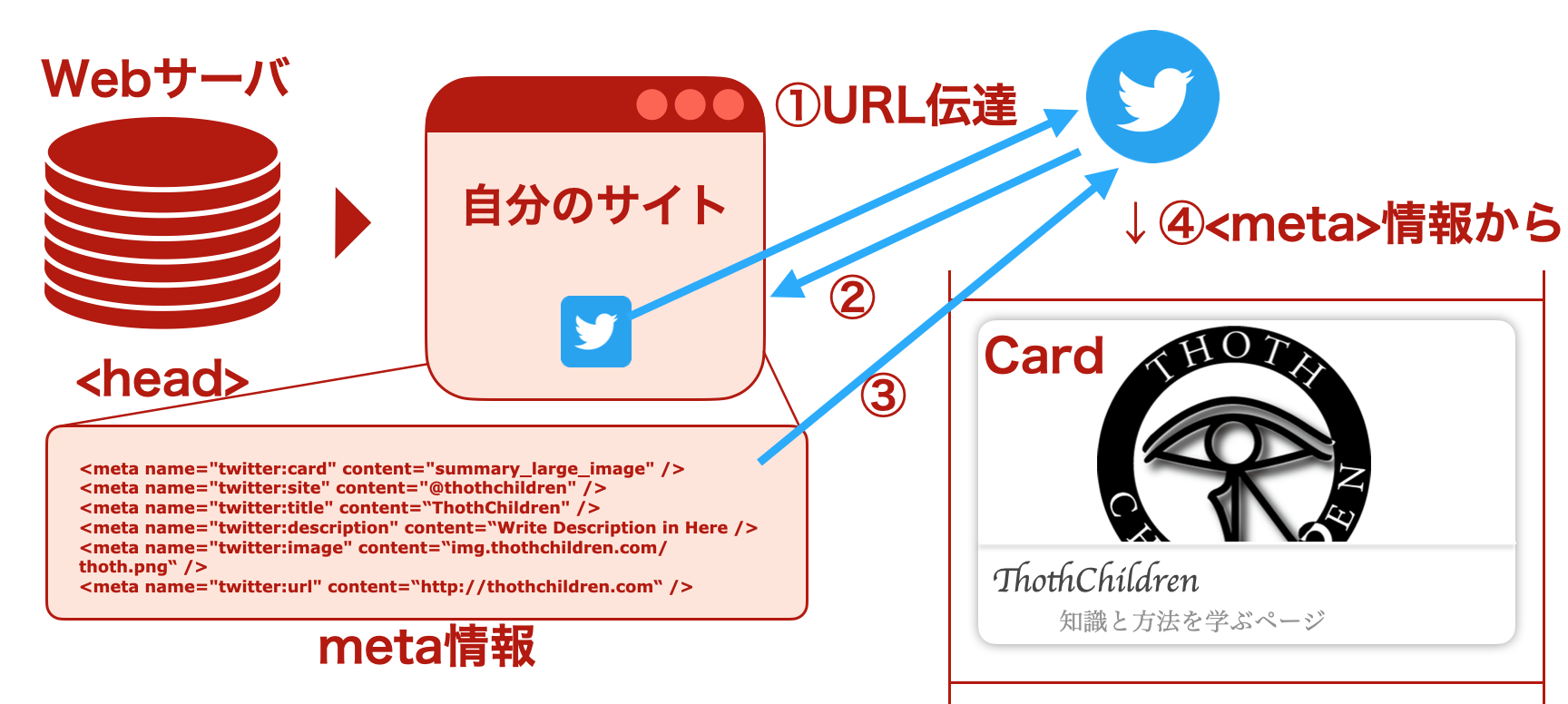
ポイント
Webでカスタムな画像分類を学習して動かしてみる
WebでDeepLearningによる画像の画像分類の転移学習でその場で学習と識別を簡単にやってみるための記事
-
Point 1ML5.jsを試用ML5.jsは誰でも簡単に最新の機械学習技術をブラウザで使うことができるライブラリ
-
Point 2MobileNet学習済みモデルで転移学習軽量で精度の高いMobile NetがML5.jsでは選択して使用することができる.ここでは学習済みのMobileNetを取得して転移学習によって再学習する非常にシンプルなサンプルを掲載
-
Point 3画像の種類を識別出力するのは与えられた画像のクラス名と確信度になります.
ステップ概要
Webでカスタムな画像分類を学習して動かしてみる
ml5.jsを使用した簡単な画像分類及び転移学習(Transfer Learning)のプログラム(HTML+JS)を準備します.
Pythonを使って簡易的なWebサーバを立てます
実行して、カスタムの学習を行いある画像のクラスと確信度表示を確認
モデルの初期化などコード全体の解説
画像分類を学習している箇所に関して解説
実際に画像分類を実行する箇所の解説
Step
画像分類プログラムを準備
今回のプログラムを使うと、自分だけの特定の識別をしたい学習器をWebブラウザで作ることができ、そのまま識別に使うことができます.つまり、ページを読み込むと画像で学習をして、その学習をもとに渡された画像の識別を行えます.
それでは早速、プログラムを用意し動かしていきます.全体の解説は追って行います.
以下のようなフォルダの構造になるように次のファイルを置いてください.
上記のindex.htmlとindex.jsはこれから実装します.
今回はラーメンとうどんを識別するためimages以下に、それぞれのフォルダを用意して、5個ずつpng画像を用意しています.これらは学習用ですが、一つ上のディレクトリにあるtest.pngは識別用です.こちらはラーメンの画像でもうどんの画像でも構いません.
これらの画像はGoogle画像検索から手でダウンロードするなどして集めてください.
続いて各ファイルの中身です.
まず,index.htmlは以下のコードとなります.
次にJavaScript側のソースコードは以下になります.
以上で準備は完了です.
それでは早速、プログラムを用意し動かしていきます.全体の解説は追って行います.
以下のようなフォルダの構造になるように次のファイルを置いてください.
Folder : 画像識別転移学習プログラムのフォルダ
index.html
index.js
images/
test.png
Ramen/
0.png
1.png
2.png
3.png
4.png
Udon/
0.png
1.png
2.png
3.png
4.png
今回はラーメンとうどんを識別するためimages以下に、それぞれのフォルダを用意して、5個ずつpng画像を用意しています.これらは学習用ですが、一つ上のディレクトリにあるtest.pngは識別用です.こちらはラーメンの画像でもうどんの画像でも構いません.
これらの画像はGoogle画像検索から手でダウンロードするなどして集めてください.
続いて各ファイルの中身です.
まず,index.htmlは以下のコードとなります.
HTML : canvasを載せたHTML
index.html
<html>
<head>
<script src="https://unpkg.com/ml5@0.2.3/dist/ml5.min.js" type="text/javascript"></script>
</head>
<body>
<div id="message">モデルロード中</div>
<script src="index.js"></script>
</body>
</html>
JavaScript : ML5.jsのCocoSSDによる物体検出を行う
index.js
const featureExtractor = ml5.featureExtractor('MobileNet', train);
const classifier = featureExtractor.classification();
const classnames = ["Ramen", "Udon"];
const filenames = ["0.png","1.png", "2.png", "3.png", "4.png"];
var totalLoss = 0;
function train() {
document.getElementById('message').innerHTML = "モデルロード完了.学習中";
featureExtractor.hiddenUnits = 100;
featureExtractor.epochs = 100;
let p = new Promise((resolve, reject) => {resolve(classifier)});
classnames.forEach((classname) => {
filenames.forEach((filename) =>{
p = p.then(train_classifier => {
return new Promise(function(resolve, reject) {
var img = new Image();
img.src = "./images/"+classname+"/"+filename;
img.onload = function() {
resolve(img);
}
img.onerror = reject
}).then(img => {
return train_classifier.addImage(img, classname);
});
});
});
});
p.then(t_classifier => {
t_classifier.train(function(lossValue) {
if (lossValue) {
document.getElementById('message').innerHTML = "学習中 : " + lossValue;
totalLoss = lossValue;
} else {
document.getElementById('message').innerHTML = '学習完了: ' + totalLoss;
classify();
}
});
});
};
function classify(){
let testImage = new Image();
testImage.onload = function(){
classifier.classify(testImage,
function(err, results) {
if (results && results[0]) {
document.getElementById('message').innerHTML =
results[0].label+" : "+(results[0].confidence*100);
}
});
};
testImage.src = "./images/test.png";
};
Step
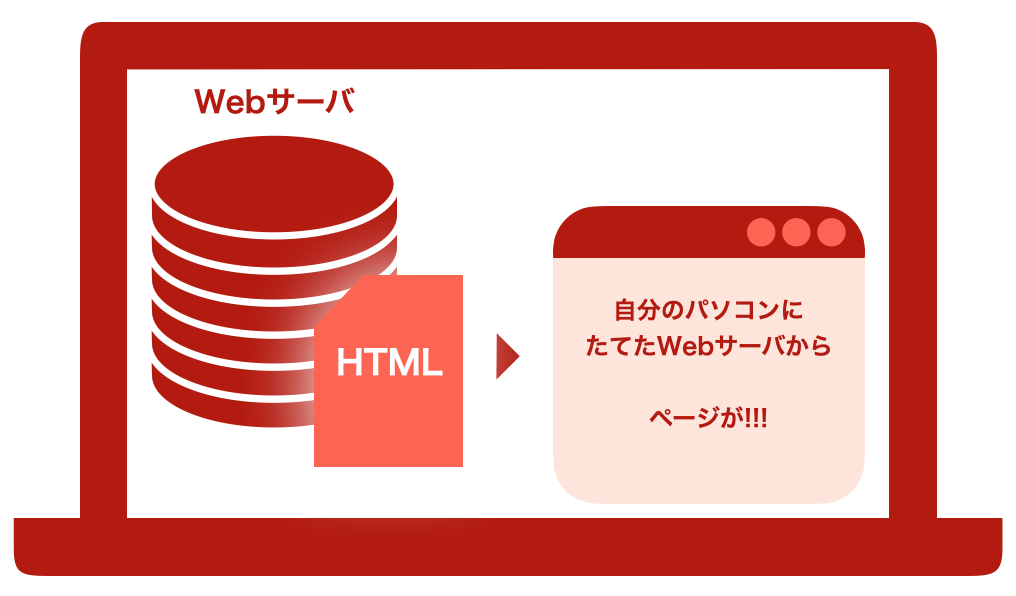
Webサーバを立てる
ここではWebサーバを最も簡単な方法で立てます.
これで簡単なWebサーバを立てることができました.
Webサーバを立てる方法について、詳しくは「とりあえずWebサーバを立ててみる」をご参照ください.
Bash : PythonでWebサーバを立てる
python3 -m http.server 8000
Webサーバを立てる方法について、詳しくは「とりあえずWebサーバを立ててみる」をご参照ください.
とりあえずWebサーバを自分のパソコンに立ててみる
自分のパソコンにとりあえずシンプルなWebサーバを立ててみるためのページです.
リンク
Step
画像分類を実行する
それではいよいよ実行します.
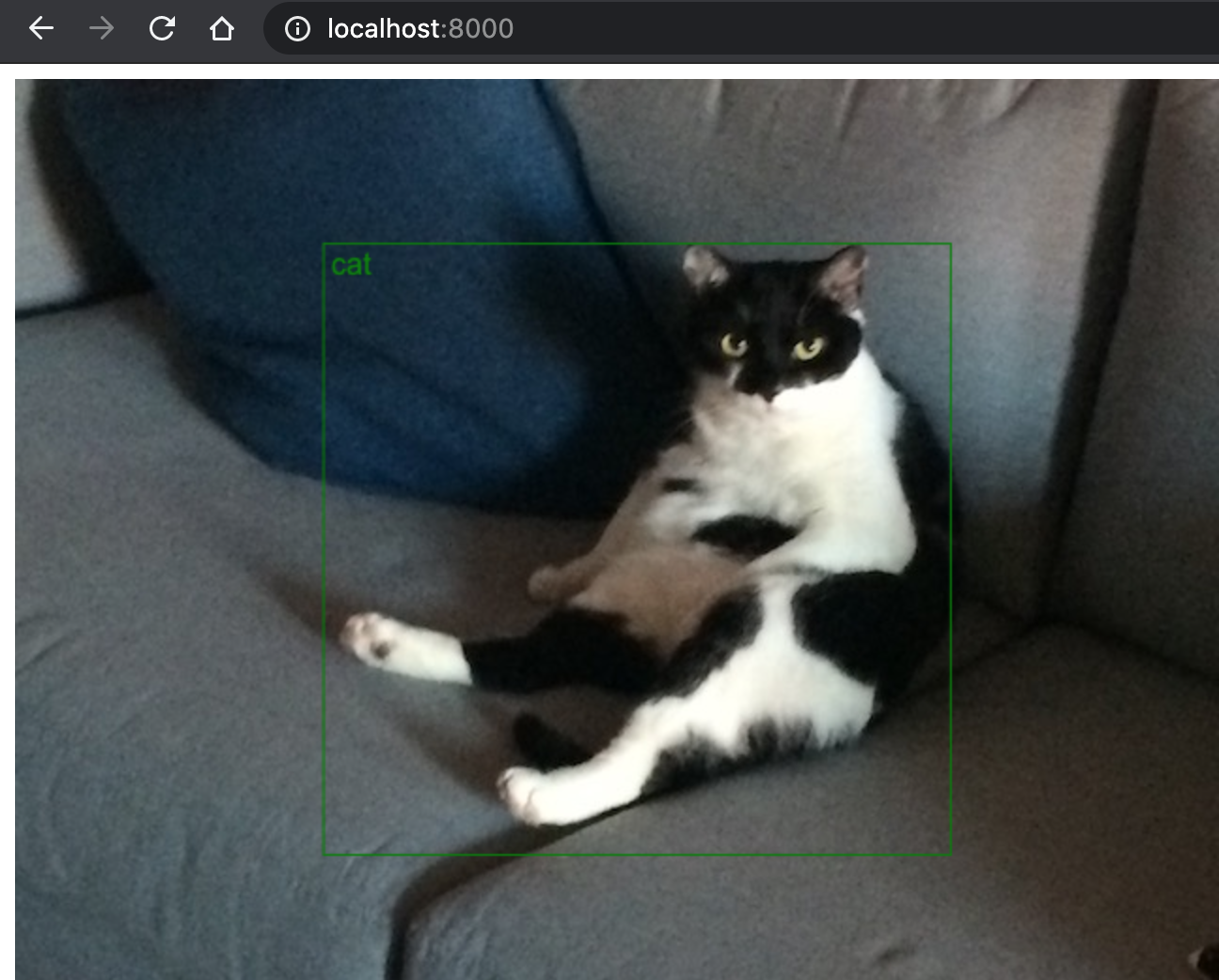
下記のアドレスをブラウザのURLバーに貼り付けて開いてください.ポート番号をStep2で変えている方は適宜8000から変更してください.
上記の実行によって以下のような画面が出ます
今回の画像がラーメンなら恐らくRamenとうどんならUdonと表示されるはずです.
![]()
下記のアドレスをブラウザのURLバーに貼り付けて開いてください.ポート番号をStep2で変えている方は適宜8000から変更してください.
: ブラウザで開く
http://localhost:8000/index.html
※
モデルをロードしまた学習するため、非常に実行に時間がかかります.
今回の画像がラーメンなら恐らくRamenとうどんならUdonと表示されるはずです.
実行結果画面
Step
コード解説:全体概要
コード全体の解説を行います
全体構成は以下のようになっています.
![]() まず初めにモデルの中心となるfeature Extractorの初期化をします.
まず初めにモデルの中心となるfeature Extractorの初期化をします.
ここではml5の特徴抽出(FeatureExtractor)モデルの初期化を行っています.
そのモデルの初期化が終わったら、train関数を呼び出します.
train関数では学習用の訓練画像を読み込み、 それを用いて全ての画像を追加後に学習を行います.
学習が終われば、最後にclassify関数で、test.pngの画像分類を行って、 その結果を表示しています.
結果ではクラス名称とともにどれくらいの確信があるかも表示しています.
全体構成は以下のようになっています.
サンプルコード全体構成
ここではml5の特徴抽出(FeatureExtractor)モデルの初期化を行っています.
そのモデルの初期化が終わったら、train関数を呼び出します.
train関数では学習用の訓練画像を読み込み、 それを用いて全ての画像を追加後に学習を行います.
学習が終われば、最後にclassify関数で、test.pngの画像分類を行って、 その結果を表示しています.
結果ではクラス名称とともにどれくらいの確信があるかも表示しています.
Step
コード解説:画像分類転移学習
まず画像分類のためのモデルをロードしているのは、以下の行です.featureExtractorの一つ目の引数がMobileNetのモデルを使うように指定しており、二つ目の引数がモデル読み込み後に呼び出されるtrain関数になります.
読み込み完了後にtrain関数の中で、複数の学習用の画像を読み込み、学習を開始しています.
まずは、画像を読み込み、モデルに与えている部分です.
classnameとfilenamesでループを行い、ラーメンとうどんのフォルダから0.pngから4.pngまでの画像を順番に取り出して処理しています
ここでは、JavaScriptで頻繁に使用されるPromiseを利用して、画像をロードして、終わったらモデルに与えるaddImage関数というのを繰り返しています.
画像のロードが終わってからモデルに与えるためにこのような形で記述しています.
これらが完了すれば、最後に学習を開始します.
上記では、モデルのtrain()関数を呼び出して、学習中や終了後に呼ばれるコールバック関数を渡しています.lossValueで学習中にどれだけ予想と実際に解離があったかが取得できます.lossValueが0になれば、学習完了となります.
学習完了したら次に画像を分類するclassify関数を呼び出します.
JavaScript : 画像分類モデル初期化
const featureExtractor = ml5.featureExtractor('MobileNet', train);
まずは、画像を読み込み、モデルに与えている部分です.
JavaScript : 学習用画像のロード
let p = new Promise((resolve, reject) => {resolve(classifier)});
classnames.forEach((classname) => {
filenames.forEach((filename) =>{
p = p.then(train_classifier => {
return new Promise(function(resolve, reject) {
var img = new Image();
img.src = "./images/"+classname+"/"+filename;
img.onload = function() {
resolve(img);
}
img.onerror = reject
}).then(img => {
return train_classifier.addImage(img, classname);
});
});
});
});
ここでは、JavaScriptで頻繁に使用されるPromiseを利用して、画像をロードして、終わったらモデルに与えるaddImage関数というのを繰り返しています.
画像のロードが終わってからモデルに与えるためにこのような形で記述しています.
これらが完了すれば、最後に学習を開始します.
JavaScript : 学習の開始
p.then(t_classifier => {
t_classifier.train(function(lossValue) {
if (lossValue) {
document.getElementById('message').innerHTML = "学習中 : " + lossValue;
totalLoss = lossValue;
} else {
document.getElementById('message').innerHTML = '学習完了: ' + totalLoss;
classify();
}
});
});
学習完了したら次に画像を分類するclassify関数を呼び出します.
Step
コード解説:画像分類実行
学習が終わったモデルを使い、分類用に読み込んだ画像を画像分類します.
testImageはImageタグをnewして保持します.このtestImageは識別する画像として渡すだけで、実際には表示しません.
次のonload関数に、画像がロードされた後に実行してほしい処理を渡しています
ここでは、モデルのclassify()関数を呼び出し、引数にtestImageを画像として渡しています.これで画像分類が実行されます.
そしてそのclassify()関数の2つ目の引数で分類が終わった後の結果を受け取り、labelとconfidenceの値を取り出して表示しています.
JavaScript : 画像分類と結果処理
function classify(){
let testImage = new Image();
testImage.onload = function(){
classifier.classify(testImage,
function(err, results) {
if (results && results[0]) {
document.getElementById('message').innerHTML =
results[0].label+" : "+(results[0].confidence*100);
}
});
};
testImage.src = "./images/test.png";
};
次のonload関数に、画像がロードされた後に実行してほしい処理を渡しています
ここでは、モデルのclassify()関数を呼び出し、引数にtestImageを画像として渡しています.これで画像分類が実行されます.
そしてそのclassify()関数の2つ目の引数で分類が終わった後の結果を受け取り、labelとconfidenceの値を取り出して表示しています.
Done