





Top
スクレイピング
スクレイピングを簡単に実行する
Pythonでスクレイピングを試す
ポイント
Pythonでスクレイピングを試す
Pythonで簡単にスクレイピングを試してみるための記事
-
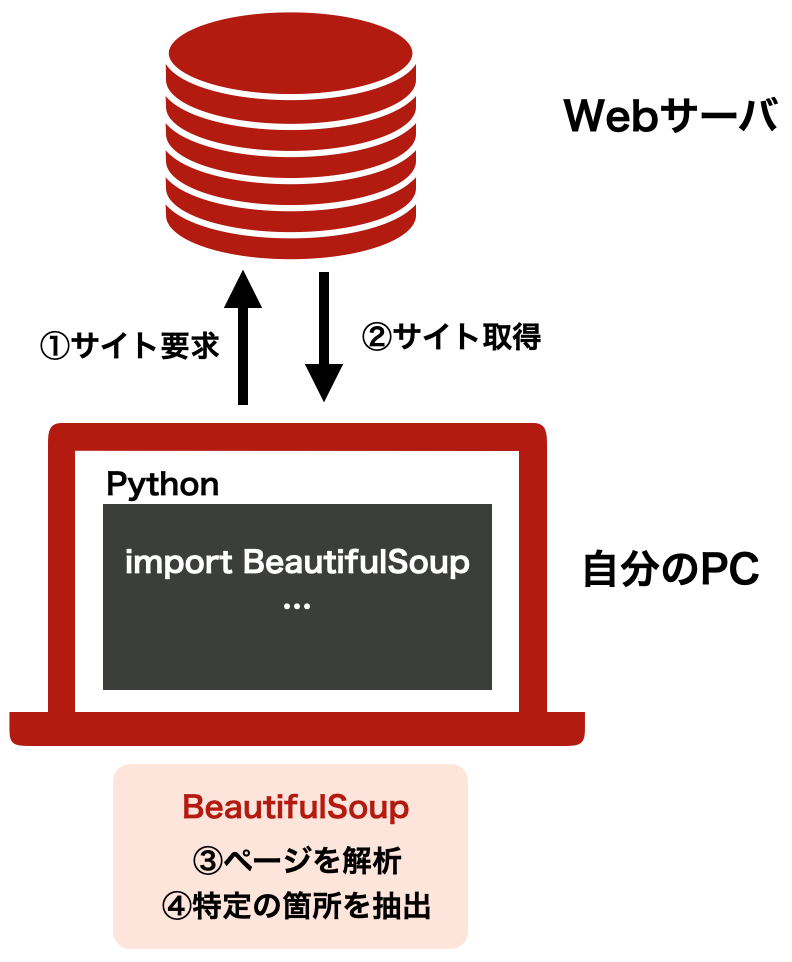
Point 1PythonでスクレイピングPythonで適当なサイトを読み出して処理する方法をお手軽に試してみます.文字列の取得、セレクタにより要素の絞り込みなどを実践します.
-
Point 2BeautifulSoupを使うよく使われるBeautifulSoupによるスクレイピングを行います.
-
Point 3タグやClassで抽出BeautifulSoupを使って、タグやClassによる抽出を行います.
ステップ概要
Pythonでスクレイピングを試す
一番初めはBeautifulSoupとrequestsのインストールから
はじめに最も基本的なdivやaタグを抽出してみます.
URLを抽出したいときなどの方法を試してみます.
CSSのセレクタと同様な抽出を試してみます.
Step
BeautifulSoupをインストール
まずPythonでBeautifulSoup4を使う準備を行います.
またサイトから情報を取得するためのrequestsもinstallしておきます.
requestsはサイトの内容を取得するためのパッケージとして、BeautifulSoup4はHTMLを解析するためにインストールしました.
またサイトから情報を取得するためのrequestsもinstallしておきます.
Bash : BeautifulSoup4のインストール
pip install beautifulsoup4
Bash : requestsのインストール
pip install requests
Step
divタグやaタグを抽出してみる
それでは早速実際にページを取得してみます.
URLは適宜それぞれの値に変更してください.いつも通りシンプルなコードになるように調整しています.
前半はrequestしたURLの中身を表示しており、後半はfind_all関数を用いてdivタグやaタグの中身を取得しています.
URLは適宜それぞれの値に変更してください.いつも通りシンプルなコードになるように調整しています.
Python : ページからdivタグやaタグを抽出してみる
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
#URLを変えてください.
URL = "xxxxxxxxx.xxxx/xxxx";
#ここでURLのコンテンツを取得
res = requests.get(URL)
#中身を表示してみます
print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
#divタグやaタグの中身を表示
print([t.get_text() for t in soup.find_all("div")])
print([t.get_text() for t in soup.find_all("a")])
Step
hrefの有無で抽出してみる
次にhrefの中身を取得します.
はじめにaタグを全て抽出してそのhrefの中身を表示します.
get関数を使えばattributeの中身を取り出します.
はじめにaタグを全て抽出してそのhrefの中身を表示します.
Python : hrefの中身を抽出する
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
#URLを変えてください
URL = "xxxxxxxxx.xxxx/xxxx";
res = requests.get(URL)
soup = BeautifulSoup(res.text, 'html.parser')
print([a.get("href") for a in soup.find_all('a')])
Step
CSSのセレクタと同じように抽出してみる
最後にClassを使って絞り込みを行います.
.bookのクラスを取得しています.
Python : hrefの中身を抽出する
#!/usr/bin/env python3
import requests
from bs4 import BeautifulSoup
#URLを変えてください
URL = "xxxxxxxxx.xxxx/xxxx";
res = requests.get(URL)
soup = BeautifulSoup(res.text, 'html.parser')
print([print(a.get_text()) for a in soup.select('.book')])
Done