-
 @ThothChildren
@ThothChildren
- 2018.6.14
- PV 189
使用単語頻度で文章がコピペ検出したい
ー 概要 ー
使用する単語の割合などを元にコピペ・盗作検出をする方法についてまとめています.Bag Of WordsやTF-IDFを用いた場合についてまとめています.



この章を学ぶ前に必要な知識
条件
- 検査対象の文章と比較対象の文章
- あらかじめ比較対象の文章は特徴量を計算しとく
効果
- 文章がコピペかどうか似ているかどうかを判定可能
ポイント
- 文章から特徴量(ベクトル)を求めてそれが類似しているかで判定
- 文章における単語の順番は気にしない
- 文章における単語の頻度に基づいて判定
- Bag Of WardsまたはTF-IFDを用いて文章の特徴を出します.
解 説
使用する単語の頻度を元に文章がコピペを検出する方法についてまとめます.
ここでは
1. 文章における単語の頻度をベクトルを算出
2. 双方(検査対象、比較対象)のベクトルによって一致率を計算
を行って単語の頻度から文章の類似度を計算し、コピペを判定します. | 使用単語頻度で文章がコピペ検出したい |
1.文章の特徴ベクトルを算出 | |
1.1.Bag of Wordsによる特徴量算出 | |
まず初めてに文章の特徴ベクトルを求めます.
Bag of Wordsでは使用される単語をベクトルにしてその文章内での頻度を計算します.
そのため、まずそれぞれの使用される回数を求めて、全体の回数で割ることによってベクトルを得ます. | Bag of Wordsによる検出 |
例 : I buy book ....... bookstore ... ...
$$\overrightarrow{ w } = ("buy", "book", ..., "bookstore")=(4, 5,..., 10)$$
$$\overrightarrow{ BOW } = (0.04, 0.05 , ...., 0.1)$$ | I buy book bookstoreのような文字列からは左のようなBOWが計算されます.単語が全部で100個あったとして計算しています. |
1.2.TF-IFDによる特徴量算出 | |
TF-IFDではBag-Of-Wordsで求めたベクトルにもう一ひねり加えています.
他の文章ではあまり使われていない珍しい単語を含んでいたらその単語の重みをあげて特徴にすることをしています.TF-IFDは単語の頻度(Term Frequency = TF)と逆頻度文書(Inverse Document Frequency = IFD)の二つから構成されていることから命名されている通りです.
これによってBOWを少し変えた特徴量を得られます. | TF-IFDによる特徴量算出 |
2.文章の類似度を算出 | |
文章の特徴ベクトルが求められたのであとは文章同士が似ているかどうかを判定することになります.
それはすなわちベクトルの類似度を求めることと同義です. | 文章の類似度を算出する |
最も有名なベクトル間の類似度はコサイン類似度です.
今回の場合にも当てはめることができ、文章のコピペの判断においてはこれで大方良さそうです. | コサイン類似度でベクトル間距離を求める |
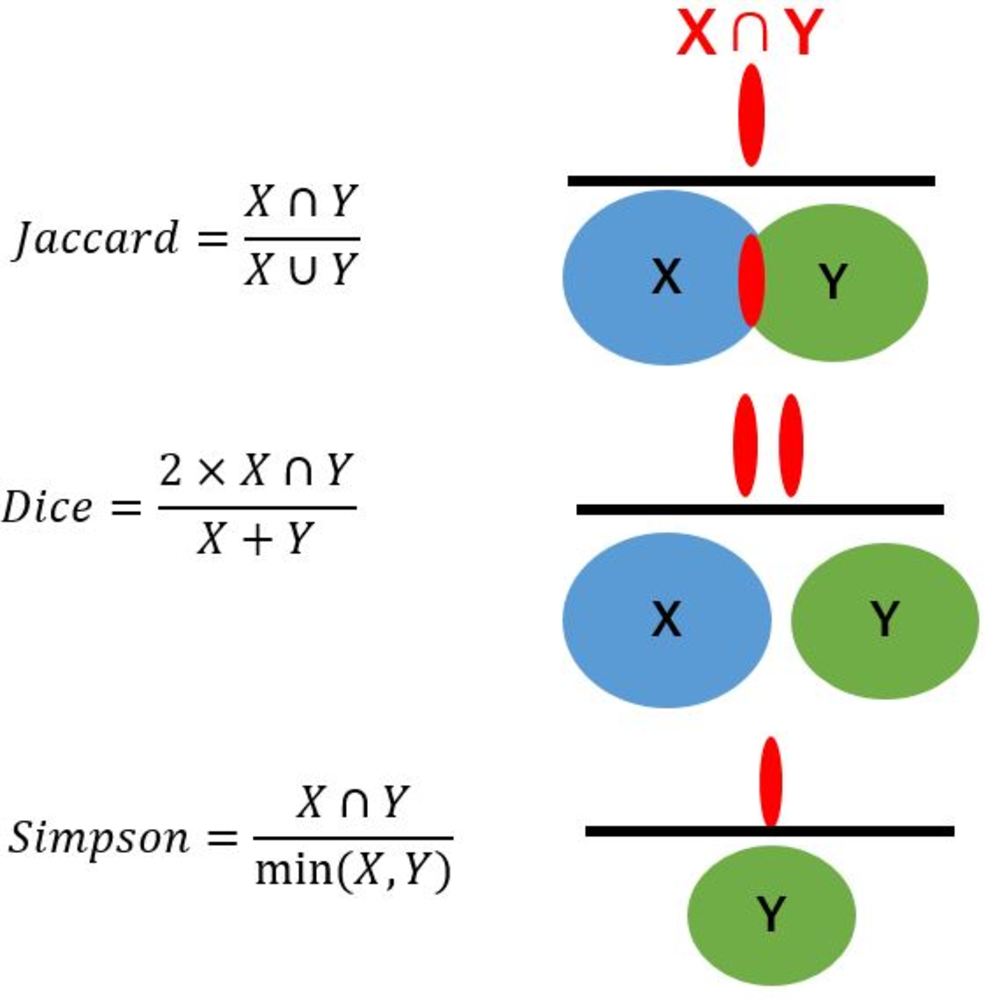
Jaccardの類似度を計算しても良いですが、
Jaccard類似度よりCosine類似度で計算した場合の方が頻度の少ないものにも重みをつけるためわずかながらよいとする論文もあります. | 集合内同一要素の数で類似度を測りたい |
この章を学んで新たに学べる
Comments
Reasons